 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing with AI: An Interaction-Based Framework for Agentic Tort Liability
May 30, 2026Agentic AI systems can plan over multiple steps, use tools, and execute tasks over time. When such systems cause harm, tort law struggles to allocate responsibility because the harmful path may be neither fully chosen by the user nor specifically foreseen by the developer. This paper proposes an interaction-based framework for agentic torts, drawing on Michael Bratman's planning theory and on the common law's treatment of human-human concerted action. We distinguish three interaction types: autonomous drift, pure tool use, and collaborative planning. Pure tool cases remain governed by ordinary product-defect and warning doctrines; collaborative planning cases map onto the independent contractor control test, professional malpractice, and negligent misrepresentation; autonomous drift maps onto frolic and detour under respondeat superior and strict product liability. The framework treats the stateful interaction log as the primary evidentiary trace, allowing courts to infer where the human-AI trajectory departed from the authorized undertaking and where liability should attach. We resolve four incident-anchored cases, situate the account alongside strict-liability and insurance-based proposals, note its relationship to regulatory oversight, and propose a ``Reasonable Agent'' standard built around constraint verification, epistemic transparency, runtime grounding, and forensic logging.
CalBench: Evaluating Coordination-Privacy Trade-offs in Multi-Agent LLMs
May 10, 2026We introduce CalBench, a controlled evaluation environment for studying multi-agent coordination through calendar scheduling. In CalBench, N agents each manage a private calendar containing pre-existing commitments and must coordinate to schedule a stream of M incoming meetings while minimizing disruption costs. Because agents observe only their own calendars, successful scheduling requires communication across private information boundaries. Each scenario is generated with an oracle solution, enabling precise measurement of coordination quality via realized-to-optimal cost, as well as a Distributed Constraint Optimization (DCOP) baseline to provide a fair comparison under the same private-information constraints. CalBench enables precise verification of task success, communication efficiency, and fairness in the distribution of disruption costs. Our environment also studies privacy-preserving coordination by augmenting calendar entries with private semantic contexts of varying sensitivity and measuring whether agents reveal task-irrelevant private information during negotiation. Unlike multi-agent benchmarks where a single capable agent can often substitute for the group, CalBench is inherently decentralized: no agent has access to another agent's private calendar, yet agents must still reach mutually consistent decisions over shared meeting scheduling. CalBench therefore provides a practical and verifiable setting for studying coordination protocols, communication efficiency, negotiation strategies, fairness, and privacy leakage in multi-agent systems.
Talk is Cheap, Communication is Hard: Dynamic Grounding Failures and Repair in Multi-Agent Negotiation
May 03, 2026Grounding is the collaborative process of establishing mutual belief sufficient for the current communicative purpose. While static grounding maps language to a shared, externally observable context, dynamic grounding is a joint activity where meaning is negotiated through interaction. Current multi-agent Large Language Model (LLM) benchmarks focus on static, one-shot tasks, overlooking the ability to repair grounding breakdowns across turns. We introduce an iterated, multi-turn negotiation game in which two agents allocate shared resources toward private projects with verifiable jointly optimal outcomes. While individual agents can identify Pareto-optimal allocations in isolation, agent dyads consistently fail to reach them across open- and closed-source models. Our investigation reveals four failure modes: (1) coordination degrades when shared interaction history is absent; (2) yet accumulated context can itself become a liability through stubborn anchoring, where initial proposals are treated as axiomatic rather than negotiable; (3) a reliance on perfunctory fairness (equal resource splits) over reward-maximizing coordination; and (4) failures in referential binding, where agents lose track of commitments across turns. These results highlight dynamic grounding as a critical and understudied axis of multi-agent coordination. Our framework decomposes the coordination gap into measurable components: the oracle baseline establishes that the gap is not attributable to individual reasoning limitations; the no-talk baseline establishes that communication is necessary; and a full-transparency intervention establishes that information exchange alone is insufficient: the bottleneck lies in the interactive processes of joint plan formation, commitment, and execution that constitute dynamic grounding.
Manifold-Aware Temporal Domain Generalization for Large Language Models
Feb 12, 2026Temporal distribution shifts are pervasive in real-world deployments of Large Language Models (LLMs), where data evolves continuously over time. While Temporal Domain Generalization (TDG) seeks to model such structured evolution, existing approaches characterize model adaptation in the full parameter space. This formulation becomes computationally infeasible for modern LLMs. This paper introduces a geometric reformulation of TDG under parameter-efficient fine-tuning. We establish that the low-dimensional temporal structure underlying model evolution can be preserved under parameter-efficient reparameterization, enabling temporal modeling without operating in the ambient parameter space. Building on this principle, we propose Manifold-aware Temporal LoRA (MaT-LoRA), which constrains temporal updates to a shared low-dimensional manifold within a low-rank adaptation subspace, and models its evolution through a structured temporal core. This reparameterization dramatically reduces temporal modeling complexity while retaining expressive power. Extensive experiments on synthetic and real-world datasets, including scientific documents, news publishers, and review ratings, demonstrate that MaT-LoRA achieves superior temporal generalization performance with practical scalability for LLMs.
Explanatory Pluralism in Explainable AI
Jun 26, 2021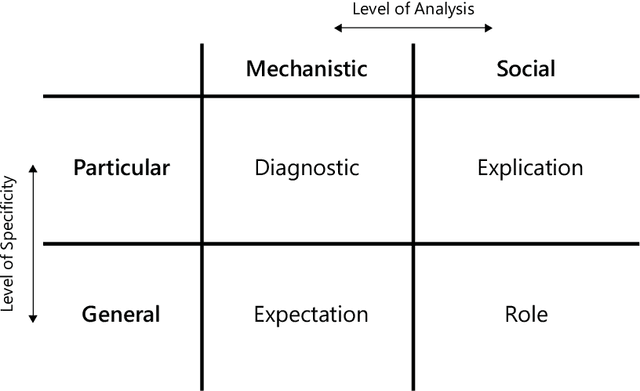

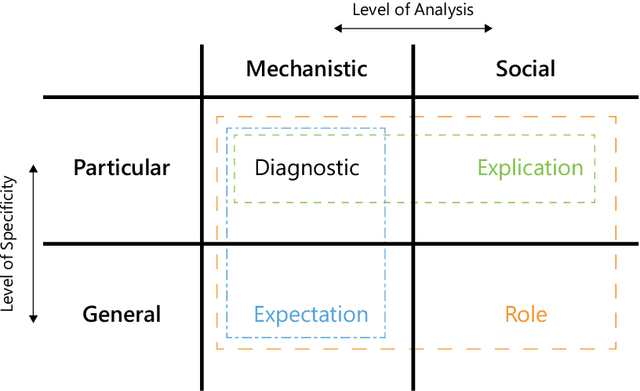
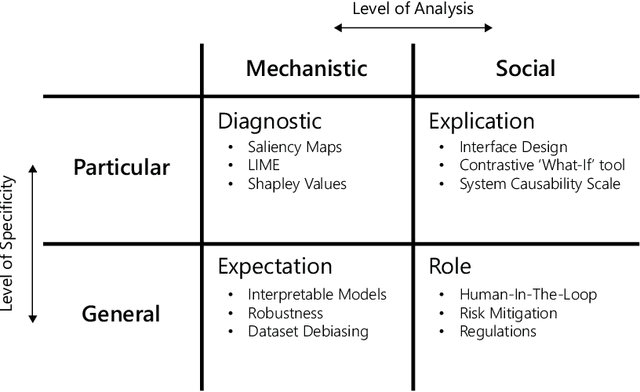
The increasingly widespread application of AI models motivates increased demand for explanations from a variety of stakeholders. However, this demand is ambiguous because there are many types of 'explanation' with different evaluative criteria. In the spirit of pluralism, I chart a taxonomy of types of explanation and the associated XAI methods that can address them. When we look to expose the inner mechanisms of AI models, we develop Diagnostic-explanations. When we seek to render model output understandable, we produce Explication-explanations. When we wish to form stable generalizations of our models, we produce Expectation-explanations. Finally, when we want to justify the usage of a model, we produce Role-explanations that situate models within their social context. The motivation for such a pluralistic view stems from a consideration of causes as manipulable relationships and the different types of explanations as identifying the relevant points in AI systems we can intervene upon to affect our desired changes. This paper reduces the ambiguity in use of the word 'explanation' in the field of XAI, allowing practitioners and stakeholders a useful template for avoiding equivocation and evaluating XAI methods and putative explanations.